1. 내장함수
[ 내장 함수]
- SQL에서는 함수의 개념을 사용하는데, 수학의 함수와 마찬가지로 특정 값이나 열의 값을 입력 받아 그 값을 계산하여 결과값을 돌려줌.
- SQL의 함수는 DBMS가 제공하는 내장 함수(build-in function)와 사용자가 필요에 따라 직접 만드는 사용자 정의 함수 (user-defined function)로 나뉨.
- SQL 내장함수는 상수나 속성 이름을 입력 값으로 받아 단일 값을 결과로 반환함.
- 모든 내장 함수는 최초에 선언될 때 유효한 입력 값을 받아야 함.
| 분류 | 설명 | 종류 |
| 단일행 함수 |
숫자 함수 | ABS, CEIL,COS, EXP, FLOOR, LN, LOG, MOD, POWER, ROUND(number), SIGN, TRUNC(number) |
| 문자 함수 (문자 반환) | CHR, CONCAT, LOWER, LPAD, LTRIM, STR, REPLACE, RPAD, RTRIM, SUBSTR, TRIM, UPPER | |
| 문자 함수 (숫자 반환) | ASCII, INSTR, LENGTH | |
| 날짜/시간 함수 | ADD_MONTHS, LAST_DAY, NEXT_DAY, ROUND(date), SYSDATE, TO_CHAR(datetime) | |
| 변환 함수 | ASCIISTR, CONVERT, TO_BINARY_DOUBLE, TO_BINARY_FLOAT, TO_CHAR(character), TO_CHAR(datetime), TO_CHAR(number), TO_DATE, TO_NUMBER | |
| 인코딩과 디코딩 | DECODE, DUMP, VSIZE | |
| NULL 관련 함수 | COALESCE, NULLIF, NVL | |
| 집계 함수 |
AVG, COUNT, CUME_DIST, FIRST, LAST, MAX, MEDIAN, MIN, PERCENT_RANK, PERCENTILE_CONT, SUM | |
| 분석 함수 |
AVG, CORR, COUNT, CUME_DIST, DENSE_RANK, FIRST, FIRST_VALUE, LAST_VALUE, LEAD, MAX, MIN, RANK, SUM | |
[ 숫자 함수 ]
| 함수 | 설명 | 예 |
| ABS(숫자) | 절대값 계산 | ABS(-4.5) = 4.5 |
| CEILING(숫자) | 숫자보다 크거나 같은 최소의 정수 | CEILING(4.1) = 5 |
| FLOOR(숫자) | 숫자보다 작거나 같은 최소의 정수 | FLOOR(4.1) = 4 |
| ROUND(숫자, m) | 숫자의 반올림, m은 반올림 기준 자릿수 | ROUND(5.36, 1) = 5.40 |
| LOG(숫자) | 숫자의 자연로그 그 값을 반환 | LOG(10) = 2.30259 |
| POWER(숫자, n) | 숫자 n 제곱 값을 계산 | POWER(2, 3) = 8 |
| SQRT(숫자) | 숫자의 제곱근 값을 계산(숫자는 양수) | SQRT(9.0) = 3.0 |
| SIGN(숫자) | 숫자가 음수면 -1, 0이면 0, 양수면 1 | SIGN(3.45) = 1 |



| 반환 구분 | 함수 | 설명 |
| 문자값 반환 함수 s : 문자열 c: 문자 n : 정수 k : 정수 |
CHR(k) | 정수 아스키 코드를 문자로 반환 CHR(68) = 'D" |
| CONCAT(s1, s2) | 두 문자열을 연결 CONCAT(''마당', '서점') = '마당 서점' | |
| INITCAP(s) | 문자열의 첫 번째 알파벳을 대문자로 변환 INITCAP('the soap') = 'The Soap' | |
| LOWER(s) | 대상 문자열을 모두 소문자로 변환 LOWER('MR.SCOTT') = 'mr.scott' | |
| LPAD(s,n,c) | 대상 문자열의 왼쪽부터 지정한 자리 수까지 지정한 문자로 채움 (예) LPAD("Page 1', 10, '*') = '****Page 1' |
|
| LTRIM(s1, s2) | 대상 문자열의 왼쪽부터 지정한 문자들을 제거 (예) LTRIM("<= =>BROWNING<= =>','<>=') = 'BROWNING <= =>' |
|
| REPLACE(s1,s2, s3) | 대상 문자열의 지정한 문자를 원하는 문자로 변경 (예) REPLACE('JACK and JUE', 'J', 'BL' ) = 'BLACK and BLUE' |
|
| RPAD(s,n,c) | 대상 문자열의 오른쪽부터 지정한 자리 수까지 지정한 문자로 채움 (예) RPAD('AbC', 5,'*') = 'AbC**' |
|
| RTRIM(s1,s2) | 대상 문자열의 오른쪽부터 지정한 문자들을 제거 (예) RTRIM('<= => BROWNING <==>','<>=') = '<==>BROWNING' |
|
| SUBSTR(s,n,k) | 대상 문자열의 지정된 자리에서부터 지정된 길이만큼 잘라서 반환 (예) SUBSTR('ABCDEFG', 3, 4) = 'CDEF' |
|
| TRIM(c FROM s) | 대상 문자열의 양쪽에서 지정된 문자를 삭제(문자열만 넣으면 기본값으로 공백 제거) (예) TRIM('=' FROM '= => BROWNING <= =') = '>BROWNING<' |
|
| UPPER(s) | 대상 문자열을 모두 대문자로 변환 (예) UPPER('mr. scott') = 'MR. SCOTT' | |
| 숫자값 반환 함수 |
ASCII(c) | 대상 알파벳 문자의 아스키 코드 값을 반환 (예) ASCII('D') = 68 |
| INSTR(s1, s2, n, k) | 문자열 중 n번째 문자부터 시작하여 찾고자 하는 문자열 s2가 k 번째 나타나는 문자. 열 위치 반환, 예제에서 3번째부터 OR 가 2번째 나타나는 자리 수 (예) INSTR("CORPORATE FLOOR', 'OR', 3, 2) = 14 |
|
| LENGTH(s) | 대상 문자열의 글자 수를 반환 (예)LENGTH('CANDIDE') = 7 |


[ 날짜 및 시간 함수 ]
| 함수 | 반환형 | 설명 |
| TO_DATE(char, datetime) | DATE | 문자형(CHAR) 데이터를 날짜형(DATE)으로 반환 TO_DATE('2014-02-14', 'yyyy-mm-dd') = 2014-02-14 |
| TO_CHAR(date, datetime) | CHAR | 날짜형(DATE) 데이터를 문자열(VARCHAR2)로 반환 TO_CHAR(TO_DATE('2014-02-14', 'yyyy-mm-dd'),'yyyymmdd') = '20140214' |
| ADD_MONTHS(date, 숫자) | DATE | date 형의 날짜에서 지정한 달만큼 더함 (1: 다음달, -1 : 이전달) ADD_MONTHS(TO_DATE('2014-02-14', 'yyyy-mm-dd'), 12) = 2015-02-14 |
| LAST_DAY(date) | DATE | date 형의 날짜에서 달의 마지막 날을 반환 LAST_DAY(TO_DATE('2014-02-14', 'yyyy-mm-dd')) = 2014-02-28 |
| SYSDATE | DATE | DBMS 시스템상의 오늘 날짜를 반환하는 인자없는 함수 SYSDATE = 14/04/20 |

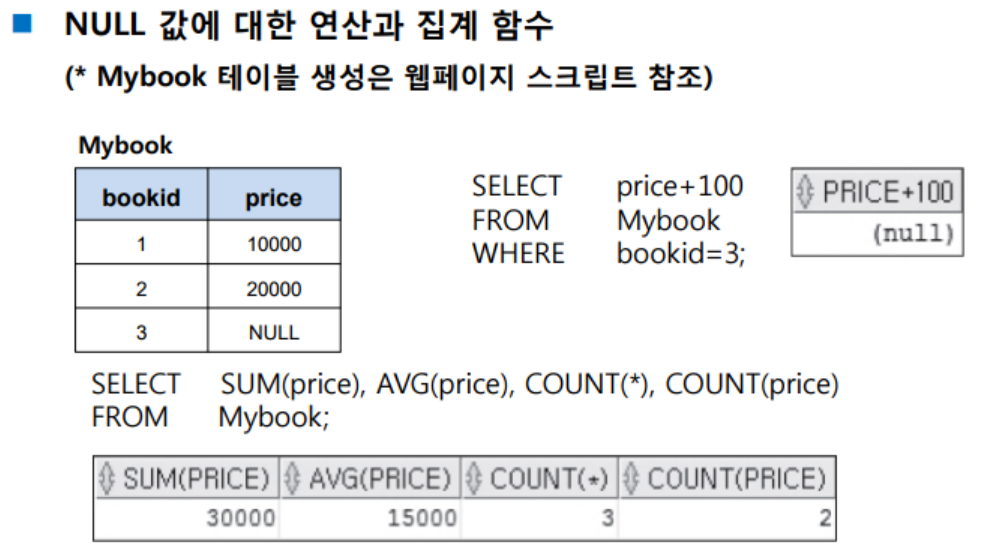
[ NULL 값 처리 ]
- NULL은 아직 지정되지 않은 값으로 0 또는 "(빈문자) 그리고 ''(공백) 과는 다른 특별한 값이다.
- NULL값은 비교 연산자로 비교가 불가능함.
- NULL값의 산술 연산을 수행하면 결과 역시 NULL 값으로 반환됨.
- NULL + 숫자 연산의 결과는 NULL
- 집계 함수 계산 시 NULL이 포함된 행은 집계에서 빠짐.
- 해당되는 행이 하나도 없을 경우 SUM, AVG 함수의 결과는 NULL이 되며, COUNT 함수의 결과는 0.




[ ROWNUM ]
- 내장 함수는 아니지만 자주 사용되는 문법임.
- 오라클에서 내부적으로 생성되는 가상 컬럼으로 SQL 조회 결과의 순번으로 나타냄.
- 자료를 일부분만 확인하여 처리할 때 유용함.

2. 부속질의
[ 부속질의(Subquery) ]
- 하나의 SQL문 안에 다른 SQL 문이 중첩된 질의를 말함.
- 다른 테이블에서 가져온 데이터로 현재 테이블에 있는 정보를 찾거나 가공할 때 사용함.
- 보통 데이터가 대량일 때 데이터를 모두 합쳐서 연산하는 조인보다 필요한 데이터만 찾아서 공급해주는 부속질의가 성능이 더 좋음.
- 주질의(Main Query, 외부질의) 와 부속질의(Sub Query, 내부 질의) 로 구성됨.

| 명칭 | 위치 | 영문 및 동의어 | 설명 |
| 스칼라 부속질의 | SELECT 절 | scalar subquery | SELECT 절에서 사용되며 단일 값을 반환 하기 떄문에 스칼라 부속질의라고 함. |
| 인라인 뷰 | FROM 절 | inline view, table subquery |
FROM 절에서 결과를 뷰(view) 형태로 반환하기 때문에 인라인 뷰라고 함. |
| 중첩질의 | WHERE 절 | nested subquery, predicate subquery |
WHERE 절에 술어와 같이 사용되며 결과를 한정시키기 위해 사용됨. 상관 혹은 비상관 형태. |
[ 스칼라 부속질의(Scalar Subquery) - SELECT 부속질의 ]
- SELECT 절에서 사용되는 부속질의로, 부속질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환함.
- 스칼라 부속질의는 원칙적으로 스칼라 값이 들어갈 수 있는 모든 곳에 사용 가능하며, 일반적으로 SELECT문과 UPDATE SET 절에 사용됨.
- 주질의와 부속질의와의 관계는 상관/비상관 모두 가능함.



[ 인라인 뷰(Inline View) - FROM 부속질의 ]
- FROM 절에서 사용되는 부속질의.
- 테이블 이름 대신 인라인 뷰 부속질의를 사용하면 보통의 테이블과 같은 형태로 사용할 수 있음.
- 부속질의 결과 반환되는 데이터는 다중 행, 다중 열이어도 상관없음.
- 다만 가상의 테이블인 뷰 형태로 제공되어 상관 부속질의로 사용될 수는 없음.


[ 중첩질의(Nested Subquery) - WHERE 부속질의 ]
- WHERE 절에서 사용되는 부속질의.
- WHERE 절은 보통 데이터를 선택하는 조건 혹은 술어 (predicate)와 같이 사용됨. 그래서 중첩질의를 술어 부속질의(Predicate subquery)라고도 함.
- 부속질의 결과 반환되는 데이터는 다중 행, 다중 열이어도 상관없음.
- 다만 가상의 테이블인 뷰 형태로 제공되어 상관 부속질의로 사용될 수는 없음.
| 술어 | 연산자 | 반환 행 | 반환 열 | 상관 |
| 비교 | =, >, <, >=, <=, < > | 단일 | 단일 | 가능 |
| 집합 | IN, NOT IN | 다중 | 단일 | 가능 |
| 한정(quantified) | ALL, SOME(ANY) | 다중 | 단일 | 가능 |
| 존재 | EXISTS, NOT EXISTS | 다중 | 다중 | 필수 |



3. 뷰
[ 뷰(View) ]
- 뷰(View)는 하나 이상의 테이블을 합하여 만든 가상의 테이블.
- 편리성: 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있기 때문에 편리함. 또 사용자가 필요한 정보만 요구에 맞게 가공하여 뷰로 만들어 쓸 수 있음.
- 재사용성: 자주 사용되는 질의를 뷰로 미리 정의해 놓을 수 있음.
- 보안성: 각 사용자별로 필요한 데이터만 선별하여 보여줄 수 있음. 중요한 질의의 경우 질의 내용을 암호화할 수 있음.


[ 뷰의 생성]

[ 뷰의 수정 ]

[ 뷰의 삭제 ]

4. 인덱스(Index)
[ 데이터베이스의 물리적 저장 ]
- 데이터가 저장되는 곳: 하드디스크, SSD, USB 메모리
- 하드디스크의 3가지 특징
- 원형의 플레이트(Plate)로 구성되어 있고, 이 플레이트는 논리적으로 트랙으로 나뉘며 트랙은 다시 몇개의 섹터로 나뉨.
- 원형의 플레이트는 초당 빠른 속도로 회전하고, 회전하는 플레이트를 하드디스크의 액세스 암(arm)과 헤더가 접근하여 원하는 섹터에서 데이터를 가져옴.
- 하드디스크에 저장된 데이터를 읽어 오는 데 걸리는 시간은 모터(Motor)에 의해서 분당 회전하는 속도 (RPM, Revolutions Per Minute), 데이터를 읽을 때 액세스 암이 이동하는 시간 (Latency time), 주기억 장치로 읽어오는 시간(Transfer Time)에 영향을 받음.

| 파일 | 설명 |
| 데이터 파일 | - 운영체제상에 물리적으로 존재 - 사용자 데이터와 개체를 저장 - 데이블과 인덱스로 구성. |
온라인 리두 로그 |
- 데이터의 모든 변경사항을 기록 - 데이터베이스 복구에 사용되는 로그 정보 저장 - 최소 두 개의 온라인 리두 로그 파일 그룹을 가짐 |
| 컨트롤 파일 | - 오라클이 필요로 하는 다른 파일들(데이터 파일, 로그 파일 등)의 위치 정보를 저장 - 데이터 베이스 구조 등의 변경사항이 있을 때 자동으로 업데이트됨 - 오라클 DB의 마운트, 오픈의 필수 파일 - 복구 시 동기화 정보 저장 |
[ 인덱스(index, 색인) ]
- 인덱스: 도서의 색인이나 사전과 같이 데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조

위의 그림과 같이 하나의 루트노드로부터 시작하여 인덱스들을 이용하여 데이터가 있는 테이블을 참조합니다. 인덱스가 데이터 테이블에 도달하기 전까지 인덱스를 점점 구체화시켜가며 최하위의 데이터 테이블에 도착하면 데이터를 참조합니다. B-Tree에서 데이터를 찾아가는 과정에 대해서는 아래에서 자세히 다루도록 하겠습니다!
[ 인덱스의 특징 ]
- 인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성함.
- 빠른 검색과 함께 효율적인 레코드 접근이 가능함.
- 순서대로 정렬된 속성과 데이터의 위치만 보유하므로 테이블보다 작은 공간을 차지함.
- 저장된 값들은 테이블의 부분집합이 됨.
- 일반적으로 B-tree 형태의 구조를 가짐
- 데이터의 수정, 삭제 등의 변경이 발생하면 인덱스의 재구성이 필요함.

자료구조 중에서 원하는 값을 최고로 빠르게 가져올 수 있는 구조가 트리구조라고 합니다. 그래서 데이터베이스의 인덱스에서도 트리구조를 활용하는데, 속성을 인덱스로 활용하여 높은 효율성을 보여줍니다. 어떤 값을 삭제 또는 변경하는 경우에 트리의 구조가 무너져서 순서대로 정렬되지 않은 트리구조로 변질될 수 있으르모 수정, 삭제와 같은 연산을 수행하는 경우에는 인덱스를 재구성해주어야 합니다.

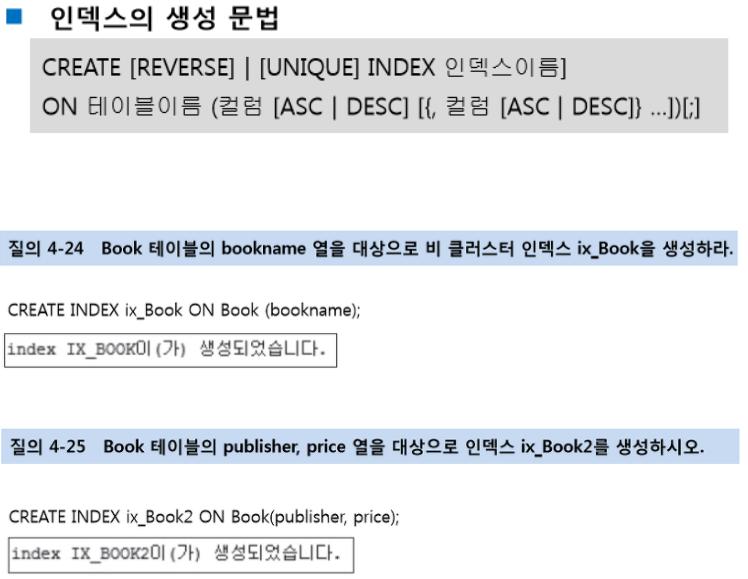
[ 인덱스의 생성 ]
- 인덱스는 WHERE절에 자주 사용되는 속성이어야 함.
- 인덱스는 Join(조인)에 자주 사용되는 속성이어야 함.
- 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음.
- 속성이 가공되는 경우에 사용하지 않음
- 속성의 선택도가 낮을 때 유리함
인덱스가 WHERE절에서 자주 사용되는 속성이어야 하는 이유는 자명합니다. WHERE절에 자주 사용되는 속성일수록 그 속성을 이용하여 접근을 많이 한다는 것이고 접근의 효율을 높이기 위해서는 그 속성을 인덱스로 사용하여 B-TREE에 접근하는 것이 최적이기 때문입니다. 조인도 마찬가지입니다. 하지만 무분별하게 인덱스를 많이 생성하면 효율이 느려질 수 있으므로 한 테이블에 4~5개를 권장합니다. 또한 속성이 가공된다는 것은 변경 또는 삭제의 연산을 의미하는데, 변경 또는 삭제 연산을 수행하는 경우에는 인덱스의 재구성을 필수적으로 해주어야 하므로 가공되지 않는 속성의 경우에 유리합니다. 또한 속성의 선택도가 낮을 때 즉, 속성의 모든 값이 다른 경우에, 하나의 인덱스 만을 사용하여 접근하므로 효율이 좋아집니다. 그러므로 선택도가 낮은 속성을 인덱스로 만드는 것이 유리합니다.
[ 인덱스의 재구성과 삭제 ]
- 인덱스의 재구성은 ALTER INDEX 명령을 사용한다.

'Be Smart > SQL' 카테고리의 다른 글
| PostgreSQL 튜토리얼 , 사용자 정의 함수 (0) | 2021.10.13 |
|---|---|
| 데이터베이스 프로그래밍 (0) | 2021.09.14 |
| SQL 기초 1 (0) | 2021.09.10 |
| SQL 문법 정리 (0) | 2021.08.04 |
| SQL 기본 쿼리문 정리-2 (0) | 2021.08.03 |




댓글